How to Exclude WordPress Content from Google Search


Sometimes you need to exclude specific WordPress content or files from being indexed in Google search results. Index, or “indexing” before the emergence of Google and other search engine was a word mostly associated with books. It usually resides at the back of most books, and this is why the Cambridge dictionary defines it in this context as:
Index: an alphabetical list, such as one printed at the back of a book showing which page a subject, name, etc. is on.
Fast forward to 1995, during the internet boom, we have services like Yahoo search engine, and come 1997, Google search has dramatically changed how we search and access information on the internet.
According to a survey done in January 2018, there are 1,805,260,010 (over 1.8 billion) websites on the internet, and many of these websites get no visitors at all.
What is Google Indexing?
There are different search engines with a different format of indexing, but the popular search engines includes, Google, Bing and for privacy-minded individuals, duckduckgo.
Google indexing generally refers to the process of adding new web pages, including digital content such as documents, videos and images, and storing them in its database. In other words, in order for your site’s content to appear on Google search results, they first need to be stored in Google index.

Google is able to index all these digital pages and content using its spiders, crawlers or bots that repeatedly crawl different websites in the Internet. These bots and crawlers do follow the website owners’ instructions on what to crawl and what should be ignored during crawling.
Why Websites Need to be Indexed?
In this era of the digital age, it’s almost impossible to navigate through billions of websites finding a particular topic and content. It will be much easier if there is a tool to show us which sites are trustworthy, which content is useful and relevant to us. That’s why Google exists and ranks websites in their search results.
Indexing becomes an indispensable part of how search engines in general and Google in particular works. It helps identify words and expressions that best describe a page, and overall contributes to page and website ranking. To appear on the first page of Google your website, including webpages and digital files such as videos, images and documents, first needs to be indexed.
Indexing is a prerequisite step for websites to rank well on search engines in general and Google in particular. Using keywords, sites can be better seen and discovered after being indexed and ranked by search engines. This then opens doors for more visitors, subscribers and potential customers for your website and business.
The best place to hide a dead body is page two of Google.
While having a lot of indexed pages doesn’t automatically make your sites rank higher, if the content of those pages is high-quality as well you can get a boost in terms of SEO.
Why & How to Block Search Engine from Indexing Content
While indexing is great for website and business owners, there are pages you may not want showing up in search results. you could risk exposing sensitive files and content on over the Internet as well. Without passwords or authentication, private content is at risk of exposure and unauthorized access if bots are given free rein over you website’s folders and files.
In the early 2000s, hackers used Google search to display credit card information from websites with simple search queries. This security flaw was used by many hackers to steal card information from e-commerce websites.
Another recent security flaw happened last year to box.com, a popular cloud storage system. The security hole was exposed by Markus Neis, threat intelligence manager for Swisscom. He reported that simple exploits of search engines including Google and Bing could expose confidential files and information of many business and individual customers.
Cases like these do happen online and can cause a loss in sales and revenue for business owners. For corporate, e-commerce and membership websites, it’s critically important to first block search indexing of sensitive content and private files and then probably put them behind a decent user authentication system.
Let’s take a look at how you can control which content and files that can be crawled and indexed by Google and other search engines.
1. Using Robots.txt For Images
Robots.txt is a file located at the root of your site providing Google, Bing and other search engines bots with instructions on what to crawl and what not. While robots.txt is usually used to control crawling traffic and web (mobile vs desktop) crawlers, it could also be used to prevent images from appearing in Google search results.
A robots.txt file of normal WordPress websites would look like this:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/The standard robots.txt file starts with an instruction for user-agent, and an asterisk symbol. The asterisk is an instruction for all bots that arrive on the website to follow all instructions provided below it.
Keep Bots Away From Specific Digital Files Using Robot.txt
Robots.txt can also be used to stop search engine crawling of digital files such as PDFs, JPEG or MP4. To block search crawling of PDF and JPEG file, this should be added to the robots.txt file:
PDF Files
User-agent: *
Disallow: /pdfs/ # Block the /pdfs/directory.
Disallow: *.pdf$ # Block pdf files from all bots. Albeit non-standard, it works for major search engines.Images
User-agent: Googlebot-Image
Disallow: /images/cats.jpg #Block cats.jpg image for Googlebot specifically.In case you want to block all .GIF images from getting indexed and showing on google image search while allowing other image formats such as JPEG and PNG, you should use the following rules:
User-agent: Googlebot-Image
Disallow: /*.gif$Important: The above snippets will simply exclude your content from being indexed by third party sites such as Google. They are still accessible if someone knows where to look. To make files private so no one can access them you would need to use another method, such as these content restriction plugins.
The Googlebot-Image can be used to block images and a particular image extension from appearing on Google image search. In case you want to exclude them from all Google searches, e.g. web search and images, it is advisable to use a Googlebot user agent instead.
Other Google user agents for different elements on a website includes Googlebot-Video for videos from applying in the Google video section on the web. Similarly, using Googlebot user-agent will block all videos from showing in google videos, web search, or mobile web search.

Please keep in mind that using Robots.txt is not an appropriate method of blocking sensitive or confidential files and content owing to the following limitations:
- Robots.txt can only instruct well-behaved crawlers; other non-compliant search engines and bots could simply ignore its instructions.
- Robots.txt does not stop your server from sending those pages and files to unauthorized users upon request.
- Search engines could still find and index the page and content you block in case they’re linked from other websites and sources.
- Robots.txt is accessible to anyone who could then read all your provided instructions and access those content and files directly
To block search indexing and protect your private information more effectively, please use the following methods instead.
2. Using no-index Meta Tag For Pages
Using no-index meta tag is a proper and more effective method to block search indexing of sensitive content on your website. Unlike the robots.txt, the no-index meta tag is placed in the <head> section of a webpage with a very simple HTML tag:
<html>
<head>
<title>...</title>
<meta name="robots" content="noindex">
</head>Any page with this instruction on the header will not appear on Google search result. Other directives such as nofollow and notranslate can also be used tell web crawlers not to crawl the links and offers translation of that page respectively.
You can instruct multiple crawlers by using multiple meta tags on a page as follows:
<html>
<head>
<title>...</title>
<meta name="googlebot" content="nofollow">
<meta name="googlebot-news" content="nosnippet">
</head>There are two ways to add this code to your website. Your first option is to create a WordPress child theme, then in your functions.php you can make use of the WordPress wp_head action hook to insert a noindex or any other meta tags. Below is an example of how you would noindex to your login page.
add_action( 'wp_head', function() {
if ( is_page( 'login' ) ) {
echo '<meta name="robots" content="noindex">';
}
} );Your second option is to use your SEO plugin to control a page’s visibility. For example, with Yoast SEO you can go to the advanced settings section on a page and simply choose “No” for the options to allow search engine to show the page:
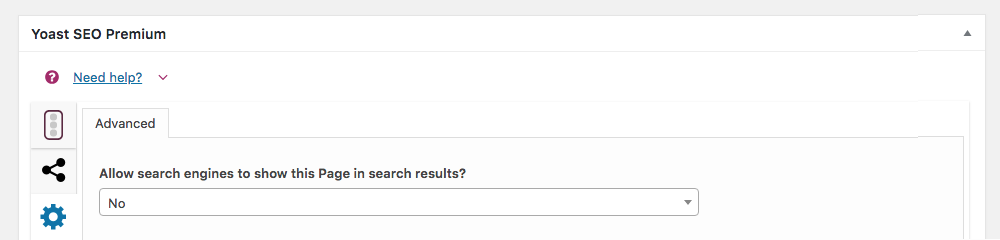
3. Using X-Robots-Tag HTTP header for other files
The X-Robots-Tag gives you more flexibility to block search indexing of your content and files. In particular, when compared to the no-index meta tag it can be used as the HTTP header response for any given URLs. For example, you can use the X-Robots-Tag for image, video and document files where it’s not possible to use the robots meta tags.
You can read Google’s full robots meta tag guide, but here’s how you can instruct crawlers not to follow and index a JPEG image using the X-Robots-Tag on its HTTP response:
HTTP/1.1 200 OK
Content-type: image/jpeg
Date: Sat, 27 Nov 2018 01:02:09 GMT
(…)
X-Robots-Tag: noindex, nofollow
(…)Any directives that could be used with an robots meta tag are applicable to an X-Robots-Tag as well. Similarly, you can instruct multiple search engine bots as well:
HTTP/1.1 200 OK
Date: Tue, 21 Sep 2018 21:09:19 GMT
(…)
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: bingbot: noindex
X-Robots-Tag: otherbot: noindex, nofollow
(…)It’s important to note that search engines bots discover the Robots meta tags and X-Robots-Tag HTTP headers during the crawling process. So if you want these bots to follow your instruction not to follow or index any confidential content and documents, you must not stop these page and file URLs from crawling.
If they’re blocked from crawling using the robots.txt file, your instructions on indexing will not be read, and so, ignored. As a result, in case other websites link to your content and documents, they will still be indexed by Google and other search engines.
4. Using .htaccess Rules for Apache Servers
You can also add X-Robots-Tag HTTP header to your .htaccess file to block crawlers from indexing pages and digital contents of your website hosted on a Apache server. Unlike no-index meta tags, .htaccess rules can be applied an entire website or a particular folder. Its support of regular expressions offers even higher flexibility for you to target multiple file types at once.
To block Googlebot, Bing and Baidu from crawling a website or special directory, use the following rules:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (googlebot|bingbot|Baiduspider) [NC]
RewriteRule .* - [R=403,L]To block search indexing of all .txt, .jpg, .jpeg, .pdf files across your whole website, add the following snippet:
<Files ~ "\.(txt|jpg|jpeg|pdf)$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>5. Using Page Authentication with Username & Password
The above methods will prevent your private content and documents from appearing in Google search results. However, any users with the link can reach your content and access your files directly. For security, it’s highly recommended you set up proper authentication with username and password as well as role access permission.

For instance, pages that includes personal profiles of staff and sensitive documents which must not be accessed by anonymous users should be pushed behind an authentication gate. So even when users somehow manage to find the pages, they will be asked for credentials before they can check out the content.
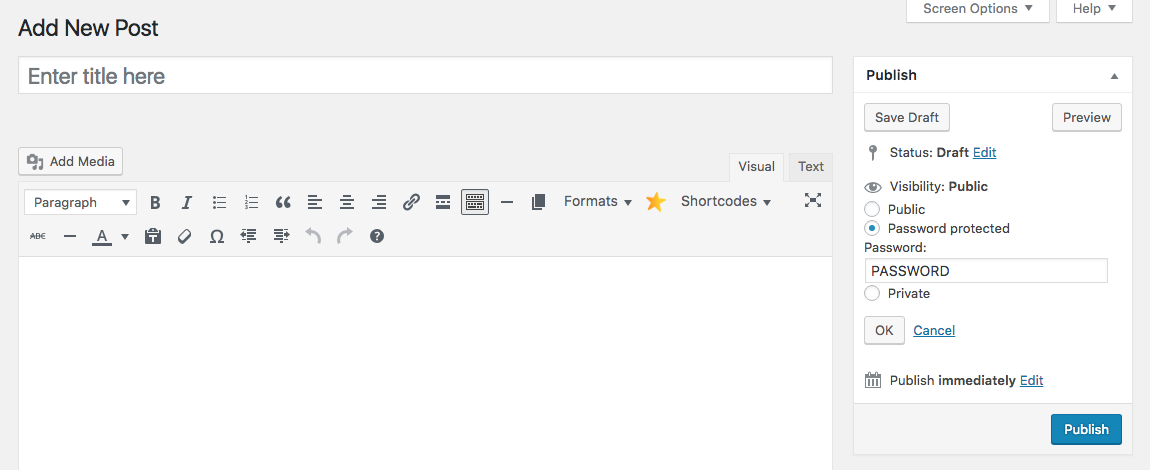
To do this with WordPress simply set the visibility of a post to password protected. This way you can select a password required to view the content on that page. This is fairly easy to do on a per-post/page basis. For more comprehensive site privacy, try adding one of these WordPress membership plugins to your website.
Please bear in mind that password-protected or hidden pages from search engines and visitors do not necessarily protect the documents, videos and images attached to its content. For real protection of your WordPress file uploads, a premium service such as Disclaimer: WPExplorer may be an affiliate for one or more products listed in the article. If you click a link and complete a purchase we could make a commission.


